ひょんなことからcromwellというScalaベースのワークフローエンジンの存在を知ったので軽く試してみました。依存関係を見るとAkka、Akka HTTP、Cats、Slickなどが使われているようです。
まずはGitHubのリリースページからcromwell-<version>.jarをダウンロードし、以下のようなシンプルなワークフローファイルを適当なファイル名(ここではhelloworld.wdlとします)で作成しておきます。
workflow myWorkflow {
call myTask
}
task myTask {
command {
echo "hello world"
}
output {
String out = read_string(stdout())
}
}
CLIからワークフローを実行してみます。
$ java -jar cromwell-<version>.jar run helloworld.wdl
するとこんな出力が得られます。
{ "outputs": { "myWorkflow.myTask.out": "hello world" }, "id": "8904c84f-933d-4228-ba4e-7eef23a8b307" }
ログを見るとデフォルトではhsqldbのインメモリモードで動作しているようです。設定ファイルのサンプルを見るとMySQLやPostgreSQLも使えるようです。
続いでサーバーモードで実行してみます。以下のようにしてサーバーを起動します。
$ java -jar cromwell-<version>.jar server
ブラウザで http://localhost:8080 にアクセスするとSwaggerのUIを参照でき、このUIからファイルを指定してワークフローを実行したり、結果を確認したりできます。
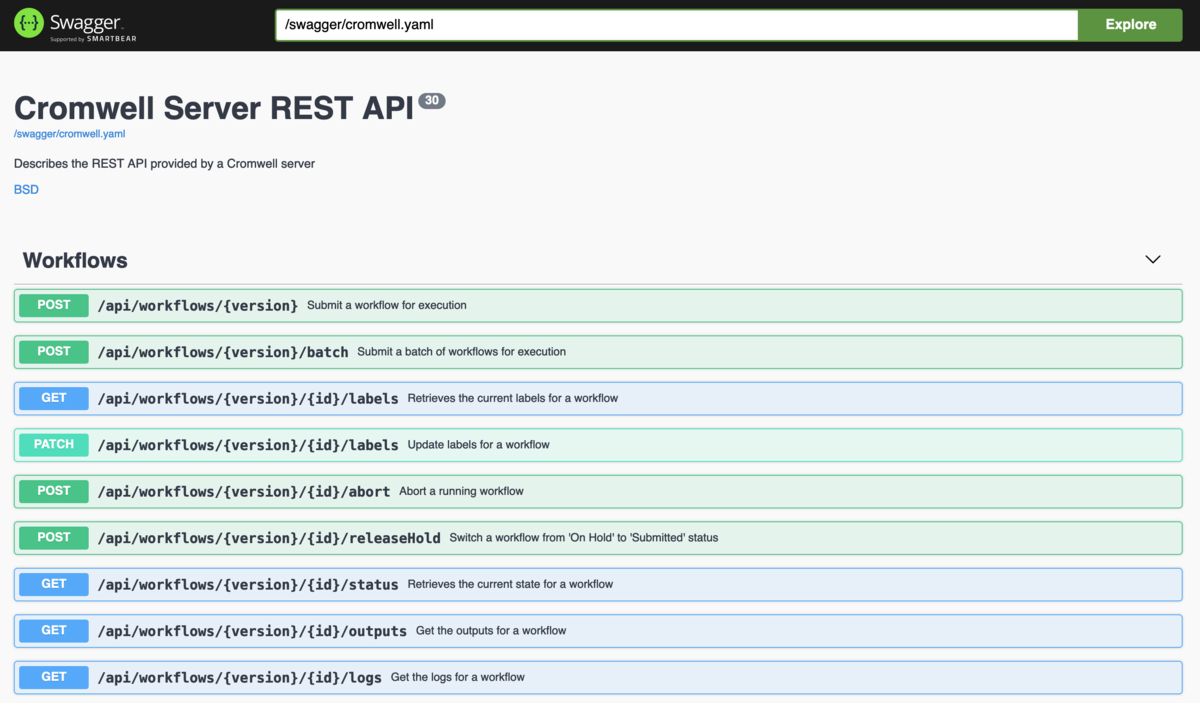
先ほどと同じワークフローをcurlコマンドで送信してみます。
$ curl -X POST http://localhost:8000/api/workflows/v1 -H "Content-Type: multipart/form-data" -F "workflowSource=@helloworld.wdl"
するとこんなJSONレスポンスが返ってきます。
{"id":"603775aa-d711-4df1-8bbb-1adad1ad7de4","status":"Submitted"}
ステータスを確認してみます。
$ curl http://localhost:8000/api/workflows/v1/603775aa-d711-4df1-8bbb-1adad1ad7de4/status {"status":"Succeeded","id":"603775aa-d711-4df1-8bbb-1adad1ad7de4"}
成功しているようなので実行結果を参照してみます。
$ curl http://localhost:8000/api/workflows/v1/603775aa-d711-4df1-8bbb-1adad1ad7de4/outputs {"outputs":{"myWorkflow.myTask.out":"hello world"},"id":"603775aa-d711-4df1-8bbb-1adad1ad7de4"}
CLIで実行した場合と同じ結果が得られました。
cromwellには様々な機能がありそうですし、WDLを使ったワークフローの記述などについてもエントリを改めてもう少し詳しく見ていきたいと思います。